
9月14日に開催されたマークアップ~フロントエンドの勉強会「SCRIPTY#6 ~フロントエンド紳士・淑女のための勉強会~」。
4番目にご紹介するのは、メディア・マーケティングソリューションズグループの岡本和昭によるセッション「ReactとImmutable.jsで関数型を体験してみて思ったこと」というタイトルで行われた発表の概要です。
JavaScriptにおける関数型のポイントを知る
現在はフロントエンジニアとして、主に広告管理ツールのフロントエンドを開発しています。業務ではReactとReduxを使っており、Immutacle.jsはまだ業務では導入していません。

まずは、JavaScriptにおける関数型の特徴について。関数型と聞くと、難しく感じる人もいるかもしれないので、簡単に説明します。
関数型とは、「1.関数→データ→関数→データと処理する設計」であり、「2.外の状態への依存や変更がないなど副作用はありません」。また「3.呼び出し元に依存せず」、「4.必ず新しい値を返す」ということ。JavaScriptでは、これらを守ることは非常に困難です。
次の例を見れば一目瞭然です(上が関数型)。悪い例では外部の変数に依存し、変更しており、値を返却していません。

先に挙げた、4個の性質が保証された関数のことを参照透過性が保たれている、といいます。このような関数は、引数が同じであれば結果は必ず同じになり、関数の役割・責任・影響範囲が明確でテストもしやすくなります。
関数型とよく比較されるのがオブジェクト指向です。オブジェクト指向はデータとそれに対する操作をひとつにまとめ、クラスとして定義します。クラスのメソッドの責務や依存もさまざま。個人的にはJavaScriptはES6やTypeScriptにより、オブジェクト指向色が強まった印象として捉えています。
JavaScriptは、関数型用に設計された言語と比べると、関数型を実装するのは難しいと感じています。また関数型言語としての機能は備わってはいますが、一方で破壊的変更も簡単にできてしまうなど問題がありました。そこで関数型を後押ししてくれるライブラリが登場しています。
それがUnderscoreやlodash、Immutableです。ImmutableはFacebookが開発したライブラリで、Reactが推奨しています。
Immutable.jsのImmutableとは不変という意味で、関数型の考えに強くインスパイアされたライブラリとなっています。最大の特徴はコレクションへの変更は必ず新しいものを返却し、元のコレクションは変更されないこと。また今回のセッションでは説明しませんが、遅延評価もサポートしています。
コードは次の通り。

プレーンなJavaScriptだと本来は同じ結果ですが、Immtableで作成したオブジェクトは不変であり、更新時には新しいモノを必ず返してくれます。オブジェクトや配列に必要な操作はひととおりそろっています。fromJS()、toJS()を利用すれば、プレーンなJSオブジェクトとの切り替えも可能です。
Immutable.jsをReactに導入する3つのメリット
では、ReactにImmutable.jsを導入した場合、どんなメリットが得られるのでしょう。まずはパフォーマンス改善です。Reactでのパフォーマンス改善と言えば、shouldComponentUpdateで、propsとstateの変更の際に、再描画判定の実行可否を決定します。
次のような単純な構造の比較だと容易ですが、valueの構造がネストすると、中身を含めたディープな比較ができないという問題点がありました。
キーを指定すればいいのですが、変更時の修正などでメンテナンスが必要になり、バグの温床になります。
Immutable.jsを活用すれば、先のようなことが解決できます。Immutable.jsであればネストしたデータはプレーンなオブジェクトではなく、Map()やList()で定義。is()を使って比較するので、正しい判定が可能になります。これであれば、ディープな部分まで比較ができ、fooが増えても気になりません。
ただ、注意点があります。
mapやList内でさらにネストした場合、それらもMapやListにしないと浅い比較になってしまい、正しく判定できません。またAPIから階層の深いJSONをまるごともらってStoreなどに突っ込む場合は、fromeJS()を使った方が楽にできるかもしれません。
そのあたりについて詳細を知りたい場合は、こちらの資料を参照してください。
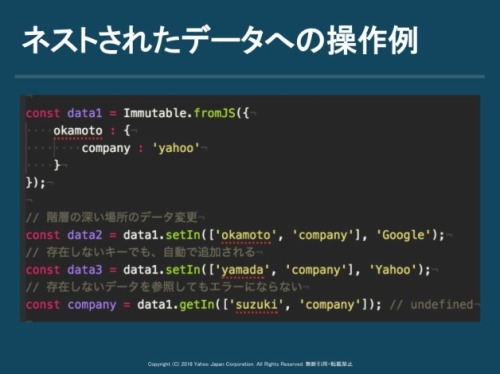
第二にネストされたデータの安全な操作が便利になることです。JSで存在しないキーの中身を参照しようとするとエラーになりますが、Immutableであれば、setIn()、getIn()で深い階層のデータ変更や参照を安全に行えます。また変更後は必ず新しいデータを返却してくれるのです。
操作例は次の通りです。
第三に、StateやStoreオブジェクトの操作が便利になることです。stateはsetStateでキーを指定して更新します。stateの中身がネストした場合、更新時にはマージする冗長なコードが増えがちになります。例えば下記のような場合を考えてみましょう。

従来のStateの操作であれば、キーを指定し、新しいStateを設定するため、現状を維持する部分とマージする部分のコードが必要になります。
一方、Immutable.jsを利用すると、捜査の結果が必ず新しい状態を返すので、直感的なコードとなります。またReduxなどのStoreオブジェクトの操作も同様にシンプルになります。
ReduxでのRecord()モデルを導入する
最後にReduxでのRecord()を利用したモデルの導入について紹介します。Reduxを導入した際に、モデルを活用することで、ロジックがAction、Store、Componentのどこかに入り、肥大化するのを解決できます。
またImmutable.Record()でデータのモデル、それを継承したクラスでデータを操作するメソッドを定義すると、ロジックを押し込むことが可能になり、肥大化が防げるのではと考えています。
例えば、todoリストStore操作にモデルを利用しないで書くと、データのインデックスを参照し、対象データを変更する冗長なコードが増えてしまいます。またこのようなコードをReducer、Actionなどどこかが必ず持つ運命となっていました。
一方、モデルを利用すると、todo自身の状態を変更する操作はモデル側で定義するだけ。edit()とsave()の操作の変更の結果をそのまま同じactionに渡すことができます。

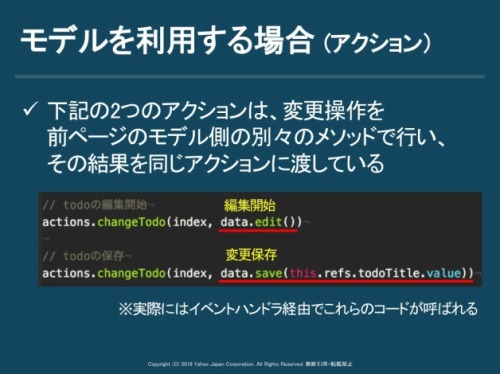
モデル側にロジックを移動したので、アクションが統合されReducerの記述が完結になり、削除など配列本体への操作も、Immutableによって完結に書くことができます。
これらモデルの利用については下記の記事が参考になりました。
* 「React使い必見! Immutable.jsでReactはもっと良くなる」
* 「How to use Immutable.js Records with React and Redux」
React+Immutableは、関数型のメリットをうまく生かすことで、コードの量や見通しが改善できそうだと感じました。ただ、途中から全てを書き換えるのはコストが大きそうなので、導入するなら早い内に導入すべきだと思います。
また、部分的にImmutableにしてしまうとプレーンなJSとの区別がつきにくいと感じました。混在する場合は、場所を区切ってデータを扱うなど、工夫が必要だと思います。
当日資料「ReactとImmutable.jsで関数型を体験してみて思ったこと」はこちら
















