プロフィール

- 宇野 秀平
検索統括本部 検索プラットフォーム開発本部 開発本部長/VPoE - 2006年入社。広告検索・商品検索・記事レコメンド・検索基盤など、主に検索関連の開発に従事。2015年度「情報検索」黒帯。2017年にメディアプラットフォーム開発本部 開発本部長に就任し、2019年より現職。
点在するデータベースを結合し、横断的かつスムーズな検索体験を提供
ヤフーの検索統括本部は、Yahoo!検索、Yahoo!広告、Yahoo!地図、Yahoo!カーナビ、Yahoo!乗換案内など、検索基盤とそれを活用したサービス・アプリを管掌する組織です。これらは多くのユーザーが一度は使ったことのあるサービスだと思います。ヤフーが持つデータは約100のサービスを横断して得られるもので、ユーザー規模も国内最大級であり、ユーザーが検索するワード数も膨大です。ユーザーの行動履歴は検索、閲覧、購買、決済領域までカバーしており、ユーザーのインサイトに基づいた、質の高いビッグデータが集まっています。入力されたユーザークエリは、サービス改善のために日々活用されています。
私たちが目指す姿は、こうしたマルチビッグデータを生かして、ユーザーに満足度No.1の検索・ナビゲーション体験を提供すること。具体的には、ユーザーが知りたいことがすぐにわかり、目的のアクションが達成できる世界です。
もちろん、それらを達成するうえで、さまざまな課題があります。現在の検索システムではまず、ユーザーがキーワードを入力すると、検索結果が表示されます。次に、ユーザーはその中にある複数のリンクをクリックし、求める情報を探し出す流れになっています。いわば、自分の頭のなかで情報を構造化しながら、それを読み解く作業が必要とされるのです。

しかし、そのレストランが子連れで利用できるか、店の外はどういった景色なのかまではわかりにくいです。その課題を解決するため、検索されたキーワードに対して、ヤフーが持つサービスのデータを生かし、Yahoo!検索ならではの独自情報を提供できるように取り組んでいます。
ヤフーには約100のサービスがあり、ローカルサービスだけでも、宿泊、旅行、飲食、美容などさまざまな情報を提供できます。レストランやホテルなどのオフィシャルな情報だけでなく、利用したユーザーの口コミも含まれます。
ただ、これまでは各サービスのデータがそれぞれのデータベースに格納されており、「点在」している状態でした。そこで、ヤフー全サービスのデータを「横断的に活用」できるように取り組んでいます。
検索で「知りたいこと」は何か。ユーザーの意図を正確に理解する
最適な検索体験を提供するためには、ユーザーの意図をデモグラフィックデータ、位置情報、検索履歴などのデータから読み解き、クエリの意図や文脈をとことん正確に理解することが必要です。検索するときに、多くの人が期待する情報を上位に表示することができれば、多くのユーザーにとって役立つ検索技術となります。そのためには、機械学習や深層学習を使ったモデルやロジックの提供が不可欠です。この点においては、AIの先端領域を極めるYahoo! JAPAN研究所と連携しながら、日々検索精度の向上に努めています。
私たちは、ヤフーが持つそれぞれのサービスが構造化されたデータを横串で接続し、融合することで可能になる検索体験を追求しています。さらにいま取り組んでいるのは、「ネットに点在するデータ」と「ヤフーが持つデータ」の融合です。
それが実現できれば、ユーザーの検索行動を次のアクションにつなげることがよりスムーズにできます。これからはそんな方向からも、検索体験の強化を進めていきたいと考えています。

Yahoo!検索が最高だと思える、サービス体験の提供を目指す
検索技術の進化は、さまざまな場面で活用できます。例えば、Yahoo!検索であるタレントの名前で検索すれば、その方に関わるニュースや動画、リアルタイムでどんなつぶやきがされているかなど検索ワードのその先に求める情報が表示されます。
これはYahoo!地図やYahoo!路線情報、Yahoo!カーナビなどのアプリでも同じです。
目的地のみならず、その先のニーズも推察し、より良い体験を作り上げることを目指しています。
ユーザーが本当に求めるクエリに対して、常に最適の回答を出してくれる。ヤフーのサービスは単なる検索サービスや地図アプリを超えた、目的達成型のサービスであり、ユーザーがそう認識してくれることで、私たちの目的も一つ達成したことになります。

社内の技術エキスパートと一緒に仕事ができる、それが醍醐味
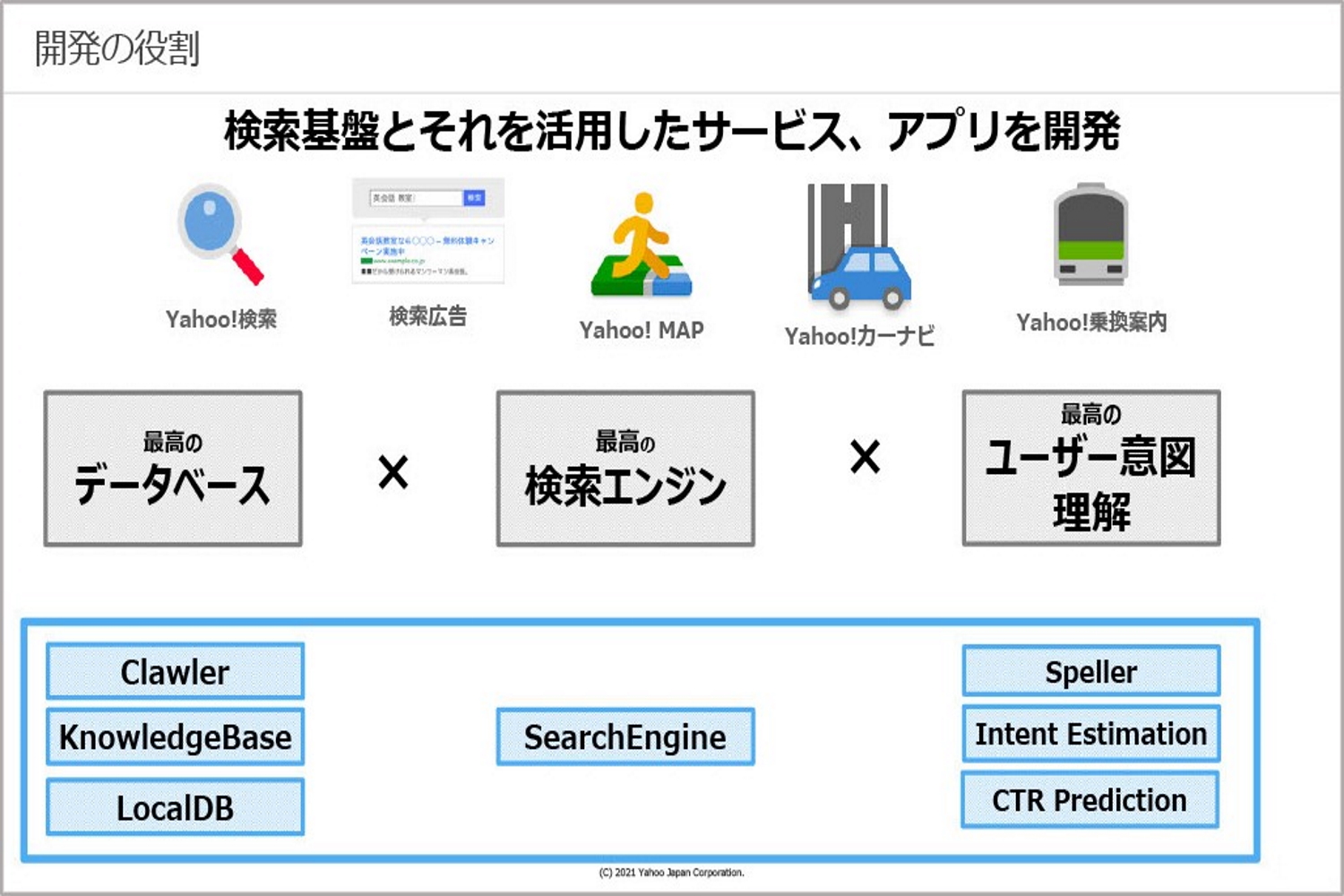
検索の新しい世界を実現するためには、横断的に使える最高のデータベースが必須となります。テキストベースのクエリだけでなく、音声入力や画像検索などさまざまなユーザーからのシグナルを認識し、それに応える最高の検索エンジン。そして、クエリの意図を見抜き、ユーザーの潜在的なニーズもくみ取るため、ユーザーの意図を理解する力が必要だと思っています。それらを実現する要素技術としては、Crawler、KnowledgeBase、Speller、Intent Estimation、CTR Predictionなどがあげられます。さらにベーシックな自然言語処理、機械学習、深層学習の知識も必要となります。
多くの自然言語処理のエキスパートが活躍していることも、強みの一つです。表記の揺れが多い日本語の検索ワードに対しても、機械学習で機能開発できることと人力での作業の切り分けを的確に判断しながら開発を進めることができます。
その環境のなかで、日本語の検索技術をエキスパートと一緒にさらに高度化できる。それはエンジニアにとって、とても重要な経験になると思います。
検索エンジンの明確なKPIに向け、技術開発が続く
検索エンジンの開発では、それぞれが明確なKPIを持って仕事に立ち向かうことも重要なポイント。検索エンジンの改良によって、クエリに対するモジュールの掲出率がどれだけ向上したかというのもKPIの一つです。例えば、商品や施設などを検索する場合、その正式名称を入力するユーザーは多くありません。名称の一部だけを入力していたり、微妙に違っていたりすることがほとんどです。そうした揺らぎ、クエリのバリエーションを吸収して、正しい名称でヒットさせるためには、モデル開発が必要です。良いモデルが開発できれば、掲出率も上がるわけです。
さらに言えば、店名や商品名などには、人間にとってもAIにとっても未知の固有名詞が存在します。そのため、ローカルサービスを提供するからには、エンジニアも世の中のトレンドを知っておく必要があります。その知見を高めるために、実は泥臭い一面もあり、そうした裏側の努力の部分も、私たちはしっかり評価していきたいと思います。

スマホアプリに関しても、デバイスやOSの進化に応じた技術のアップデートは欠かせないと思っています。AIの最先端技術はもとより、独自の検索技術を磨ける環境がヤフーにはあります。その規模と技術の奥深さにおいては、国内トップレベルのプレーヤーだと私たちは自負しています。
その技術開発の成果が日々のユーザー体験の向上につながることが、目に見えてわかる。これはエンジニアにとってとても面白いと思います。「検索技術を極めたいなら、ヤフーでしょ」って、声を大にして言いたいですね(笑)。