
同統括本部では、ビッグデータの利活用を進めるための研究および技術開発が行われています。その内容をわかりやすく伝えるため、7月8日に「Yahoo! JAPAN データ&サイエンス向けポスターセッション」を、ヤフーのインターンシップ応募者限定で開催し、当日はデータ&サイエンスに興味を持つ学生が100名以上集まりました。
ポスターセッションでヤフーの取り組みをわかりやすく伝えたい
ポスターセッションとは、A0サイズの紙1枚に発表内容をわかりやすくまとめて貼り出し、その内容を聞きに来た人に適宜説明を行うもの。学術会議の成果発表でもよく用いられている方式です。

今回のイベントで、なぜこの方式を採用したのか。同イベント運用担当であるデータ&サイエンスソリューション統括本部で部長を務める野口は次のように語っています。
「当部署では定期的に外部向けに情報を発信するイベントを開催しています。昨年11月にはカンファレンスを開催。その際に、トークセッションだけではなく、ポスターセッションも取り入れたんです。
社内向けにはすでに5回、ポスターセッションを開催してきました。ポスターセッションの良いところは、トークセッションとは異なり、その場で気軽に質問ができること。しかも参加者は自分の興味のある分野の話だけを選択して聞くことができます。そこで今回はこの形式を採用することにしました」

今回のインターン生向けポスターセッションの最大の目的は、学生にヤフーの取り組みを知ってもらうこと。それと同時に「せっかくインターンに来てもらうのであれば、学生の興味と受け入れ側が期待することのミスマッチをできるだけなくしたいという思いがあったのです」と、野口は言います。
したがって、ポスターセッションに登場したのは「インターン生の受け入れを考えているチーム」。ポスターの内容もインターンシップで携わってもらう業務に近い内容のテーマを選んで発表しています。
今回はその技術・研究内容から、三つのポスター内容を紹介したいと思います。セマンティックウェブによる、回答力強化プロジェクト
まずは「ウェブ検索回答力強化にむけた取り組み」。同プロジェクトに所属している西が内容の説明をしました。

回答力を強化する目的は、検索意図を理解し、ユーザーのニーズに直接応えることで、より満足度の高いウェブ検索サービスを提供することです。
これに欠かせない技術がセマンティックウェブです。セマンティックウェブとは、情報の意味をコンピューターが自律的に理解できるようにするための技術。そのために現在、世の中のエンティティの関係をたどれるグラフ上のデータベース「社内ナレッジデータベース」の構築と「検索クエリ意図解釈」の研究に取り組んでいます。
ナレッジデータベースとは世の中のエンティティの関係をたどれるグラフ上のデータベース。そして後者の検索クエリ意図解釈技術により、検索クエリの意図を解釈してナレッジベースと関連付けることで、適切な回答を表示できるようにするのです。
例えば「俳優Aと俳優Bが共演した作品の一覧が欲しい」というクエリに対して正しく回答することはもちろん、作品について詳しく知りたいという人に対しては、映画やアニメなどジャンル別に整理して回答したりすることが可能になります。
技術課題もまだまだ残っています。ナレッジベースについては自然言語処理を活用したウェブ上の文章からの情報抽出、ウェブデータからのエンティティ画像獲得、データ品質の担保など。
またクエリ解釈については、複数単語クエリの適切な解釈、意図解釈のパーソナライズ、コンテキストによる意図の違いの解釈、自然語による検索の解釈などが挙げられます。
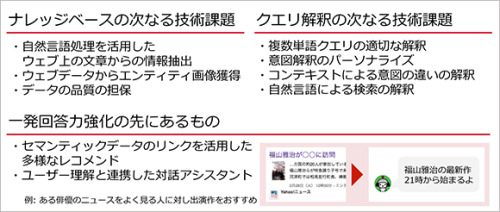
そして最終的には、セマンティックデータのリンクを活用した多様なレコメンド、ユーザー理解と連携した対話アシスタントの実現を目指していきます。
西たちのチームはナレッジベースの構築を担当。西はこのプロジェクトに入って3年目となります。学生時代の専門は機械学習でした。その後、ヤフーに入ってからはナレッジベース構築のチームに所属しています。

ナレッジベースは非常にホットな研究分野。セマンティックウェブや自然言語処理の知識がある人はもちろん、知識がなくてもこの分野に興味を持ち、論文を読むなど勉強しながら自分のアイデアを試したいという人なら活躍できると思います。
ヤフーの音声認識サービス「YJVOICE」の開発
次は三宅純平の「ヤフー音声認識YJVOICEの取り組み」です。

ヤフーでは、2011年3月から音声認識サービスを提供しています。認識できる語彙(単語数)は100万語以上。同サービスはヤフーが提供するスマートフォンアプリのうち、約15個に導入されています。
音声認識技術は言語モデルと音響モデルが重要な要素技術です。「YJVOICE」の言語モデル・単語辞書は大規模Web検索ログコーパスなどから学習させているのが特徴で、音響モデルでは、音素を識別するために約2000時間の音声データからディープラーニング技術を使ってモデル学習させているのが特徴です。
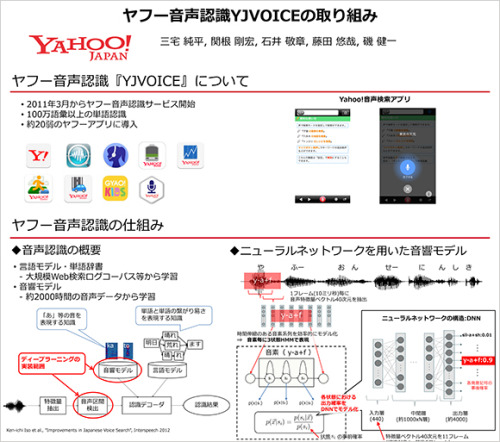
また、音声の発話区間の検出にもディープラーニングが活用されています。
音声認識はパターン認識の一つで、基本的には音声データがあればあるほど認識精度を高めることに期待ができます。ヤフーでは6年前から音声認識サービスを提供しているので、音声データも豊富に蓄積しています。したがってヤフーは音声認識技術の開発や研究をする上で、データの強みを生かせる有利な環境にあります。
現在、三宅たちのプロジェクトが目指しているのは雑音下における遠距離発話でも精度の高い音声認識の実現です。そのための研究テーマの一つはLSTM(Long short-term memory)というニューラルネットワークの技術を利用したキーワードスポッティングです。あらかじめ固定したキーワードで話しかけると、それがトリガーになり音声コマンド等のアクション機能が利用できるような仕組みの開発です。これにより、自動運転中などハンズフリーの音声コマンドも有効になります。
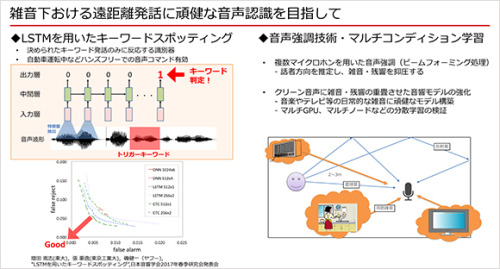
ヤフーではスマートフォン向けの音声認識技術はほぼ実用レベルに達していますが、今後は雑音環境下で話者とマイクは離れた状態でも音声認識ができるような技術の開発を目指しています。
そのためには複数マイクロホンを用いて話者方向を推定し、雑音・残響を抑圧することが必要となります。また音楽やテレビなどの日常的な雑音に頑強な音響モデルを構築する必要もあります。クリーン音声に雑音・残響を重畳させて大規模にデータ拡張してモデル学習をしますが、現実的な時間で学習が終わらせられるようにマルチGPU、マルチノードなどの分散学習の検証も行っています。

三宅が学生時代に専門としていたのは音声認識。2009年にヤフーに入社してからは、クエリのよい区切り方を推定する日本語処理の研究開発に従事していました。その後、ヤフー研究所主導の音声プロジェクトの立ち上がりと共に異動し、音声認識の開発に従事しています。
実は日本語処理も音声認識には欠かせない分野。というのも音声認識技術にはパターン認識や音声信号処理、日本語処理、探索アルゴリズムなどのさまざまな技術要素が必要となるからです。
音声認識は今まさに市場としても最も盛り上がっている分野であり、ニューラルネットワークベースの新しい音声認識のアーキテクチャも登場しています。
音声認識技術を追求するには、ヤフーは最適な場所です。それはデータをたくさん持っていることに加え、最近だとスーパーコンピューターを有しているなど計算機環境のインフラも整備されているからです。
「まだヤフーは音声認識分野では若い会社ですので、音声認識チームの強化にも努めています。興味のある方はぜひ一緒に開発していただきたい。」と三宅は期待を語りました。
Solrを用いた全社検索基盤の構築プロジェクト
最後に紹介するのは、「Solrを用いた検索基盤構築の取り組み」。このプロジェクトについて紹介してくれたのは矢野友貴です。

ヤフーでは今後のデータ増加に備え、検索システムの強化を図ると共に、検索でのサービス横断的なデータ利活用を促進したいと考えていました。そこで全社サービスを支える新しい検索基盤の構築に取り組んでいます。
新しい検索基盤に求められる条件は三つ。
第一は多様なサービスのニーズに応える機能性です。ヤフーが提供している多様なサービスに対応するためには、柔軟性が不可欠だからです。
第二に膨大なデータに耐えうる検索性能。たとえばYahoo!ショッピングは3年で商品点数が約3倍になるなど、現在も規模が拡大しています。
第三は容易にデータの利活用ができること。Yahoo! JAPANのサービスは流動的で、検索側が日々のユーザーの変化に追随できることが重要です。
今回、この新しい検索基盤を構築するために活用したのが、世界的に多くの利用実績があるOSSの検索エンジン「Apache Solr」でした。Solrを活用するにあたり、Solrコミュニティーへの貢献も同プロジェクトの柱として位置づけられました。
プロジェクトに取り組んで約1年。代表的な成果を二つご紹介します。ひとつめは、ランキングプラグインという、検索結果をスコアリングして順位付けする仕組みです。

ヤフーでは、サービスによって検索で利用されるスコアリングの計算式(検索モデル)が異なるため、これらを検索エンジン側で柔軟かつ簡単に定義する仕組みが必要でした。
プラグインでは、これら多種多様な検索モデルを記述するために専用の言語(DSL、Domain Specific Language)を提供しています。この技術に関しては、将来的にオープン化してSolrコミュニティーに還元する予定です。
もう一つの成果は、Solrの部分更新の高速化です。開発当初に問題となったのは、Solrの部分更新の遅さです。ヤフオク!の入札額の更新など、ヤフーが提供するサービスの中には、部分更新が遅いと致命的になるものがあるからです。
そこで、Solrのコードを細かくプロファイリングしてボトルネック箇所を特定し、改修を行いました。すると、部分更新の速度が100倍程度改善。副次的な効果として、検索レイテンシも20%ほど改善しました。この改修はSolrコミュニティーにパッチとして提供済みで、現在の最新バージョンでは実際にSolr本体に取り込まれています。
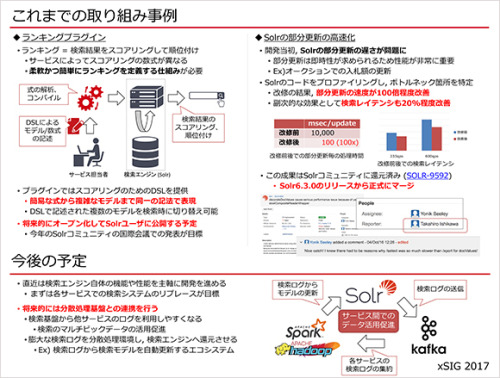
今後の予定としては検索エンジン自体の機能や性能を主軸に開発を進めていき、各サービスでの検索システムのリプレイスを行っていく予定です。
そして将来的には分散処理基盤との連携を行い、分散処理基盤での検索ログの解析、解析結果に基づく検索エンジンの改善、新たな検索ログの蓄積、という継続的な改善サイクルを実現するエコスステムを構築していくことを考えています。
通常、検索エンジンを使うことはあっても、開発することはほとんどないでしょう。ですが、ヤフーであれば検索エンジン自体を開発できる。そこが面白さです。
また、実際に検索エンジン自体に手を加えることができるので、自分が考えたアイデアを形にしやすいところにも、ヤフーでの仕事の面白さがあります。

検索基盤の構築といっても、検索モデルを作る人もいれば、検索エンジンの開発に従事する人など、その役割はさまざま。従って、求められる技術範囲も広いのです。プログラミングの知識がある人、データ解析に関心のある人、機械学習の知識のある人など、さまざまな人が活躍できる可能性があります。
矢野は、前職ではシステムエンジニアとしてシステム開発に従事していました。ヤフーに入り、検索エンジンや機械学習に触れる機会を得て、サイエンス分野の社内公募に手を挙げて今のポジションに着きました。自分のやりたいことができる環境がヤフーにはあるのです。
対象を広げ、ポスターセッションを開催したい
今回のイベントでは、海外の学会で発表したポスターも貼り出されました。
ヤフーにはYahoo! JAPAN研究所があり、そこでは日々、蓄積される膨大なデータやユーザーの声などを成果につなげるため、各サービス部門、大学・研究機関と連携し、研究開発を進めています。
その成果を論文としてまとめ、国内外に発信しています。インターネット関連技術の発展において、ヤフーがいかにグローバルで貢献しているのか、学生にも知ってもらえる機会になったのではないかと思います。
「今回はインターンシップの応募者を対象としましたが、今後は大学の研究者や社会人向けにも対象を広げていきたいと思います。社内外のさまざまな人たちとつながり、コラボレーションできれば、私たちの研究開発が加速するだけではなく、社会により大きな貢献ができると思うからです。ぜひ、次回の開催も期待してください」(野口)



















