
こんにちは、「Yahoo! JAPANビッグデータレポート」チームです。
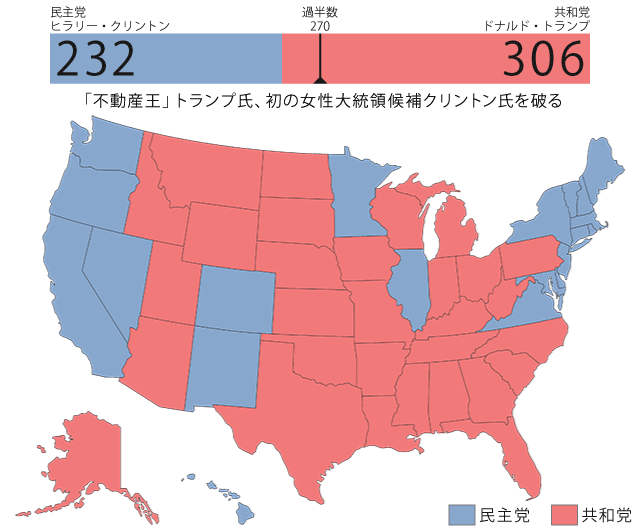
去る2016年11月8日、世界的に注目を集めたアメリカ合衆国大統領選挙(以下、米大統領選)が行われ、共和党のドナルド・トランプ氏が勝利しました。
(図1)2016年11月米大統領選結果
- 資料:
- 朝日新聞デジタル(2016年11月29日)を元にヤフーが作成
これは、おおかたの予測に反する結果でした。主要メディアの事前調査の多くはクリントン候補優勢と伝えていました。また、選挙予測で有名なネイト・シルバー氏もクリントン優勢との予測(外部サイト)をしており、結果的にヨミが外れた形です。
なぜ、今回の米大統領選ではさまざまな予測が外れたのでしょうか?トランプ氏の勝利をデータから正しく予測することは可能だったのでしょうか?私たちは統計的な観点から米大統領選を検証してみることにしました。
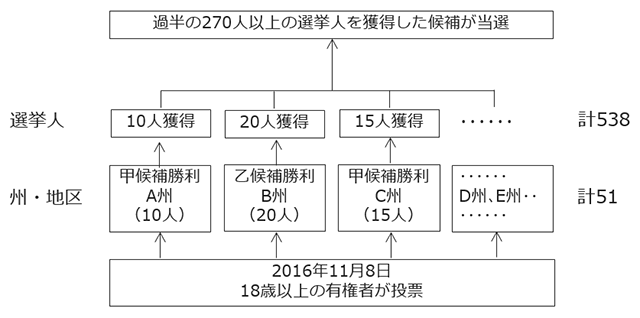
前提として、米大統領選挙の仕組みをおさらいしておきましょう。
民主・共和両党から候補者を1名に絞るための予備選挙を行ってから、本選挙が実施されます(図2)。
(図2)米大統領選挙 本選挙の仕組み
- 資料:
- 日本経済新聞(2016年11月6日)を元にヤフーが作成
本選挙は、間接選挙方式で行われます。間接選挙方式とは、各州の代表者である538人の選挙人が大統領を選ぶ形式です。選挙人はあらかじめ指名候補(政党)を誓約しています。
有権者は支持する大統領候補に投票します。州ごとに得票数で1票でも上回った候補者が、その州に割り当てられた選挙人の数を総取りする仕組みです。この総取り方式のため、今回のように全米の得票数では下回る候補者が勝利するケースもあり、批判の声も上がっています(なお、ネブラスカ州とメーン州は有権者の得票に応じた比例割り当て方式を採用しています)。選挙人のうち過半数の270人を獲れば勝ちとなります。
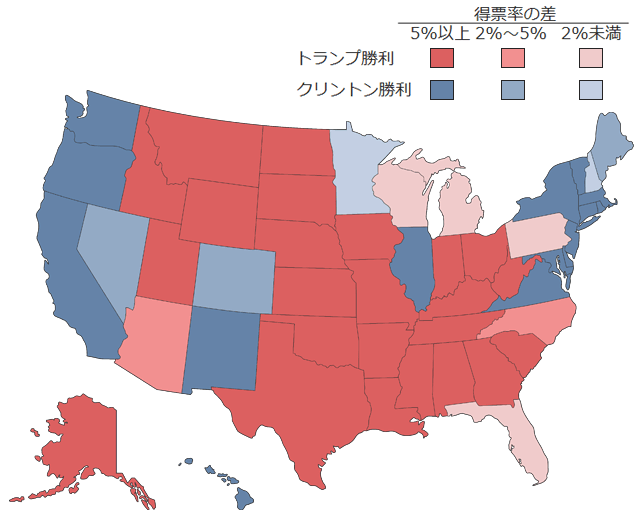
今回の米大統領選の州ごとの得票率を見てみると、決してトランプ氏の圧勝ではなく、実は僅差による勝利も多かったことがわかります(図3)。
(図3)2016年11月米大統領選の得票率(%)
- 資料:
- political report tracker 2016/11/24現在
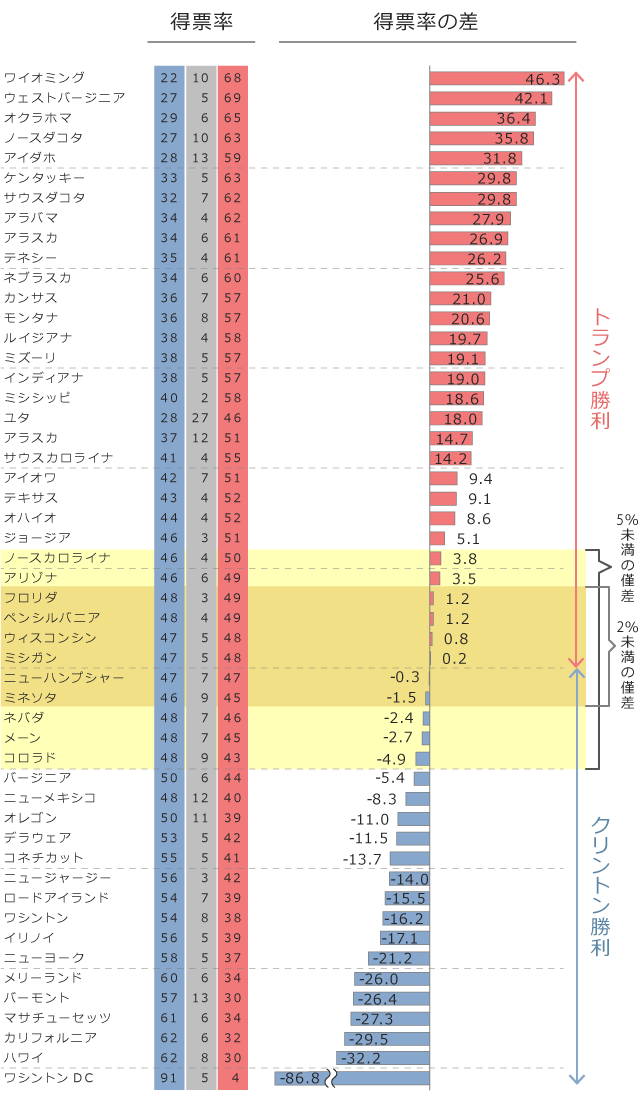
51州のうち、11州が得票率の差5%未満、6州が得票率の差2%未満の僅差でした。ミシガン州やニューハンプシャー州のように、その差がわずか0.2~0.3%の州もありました(図4)。
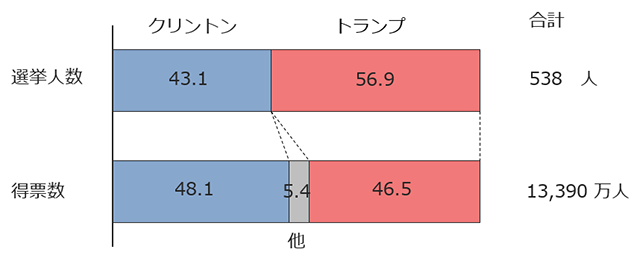
先ほど説明したとおり、たとえ僅差であっても勝者が州の選挙人を総取りします。そのため、全米での得票数ではクリントン氏がトランプ氏を上回ったにも関わらず、選挙人の数ではトランプ氏が過半数を獲得し、勝利を収めました(図5)。
クリントン氏優勢としていた各種の事前調査は、方向性としてはむしろ正しかったということになります。
(図4)2016.11 米大統領選挙の州別得票率(%)
- 資料:
- political report tracker 2016/11/24現在
(図5)2016.11 米大統領選挙の結果まとめ(%)
- 資料:
- political report tracker 2016/11/24現在
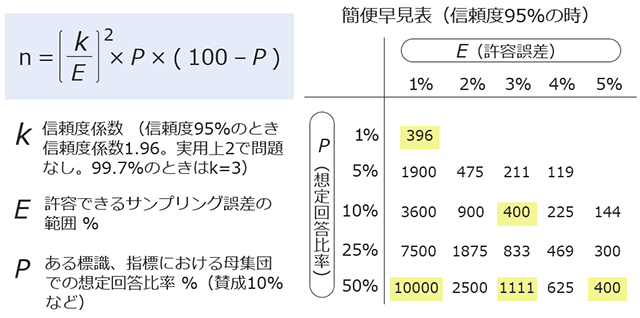
このような僅差の勝負を事前調査データから予測することは可能だったのでしょうか。ここで許容誤差とサンプルサイズについてお話します(図6)。
許容誤差(E)とは、「許容できるサンプリング誤差の範囲」を表します。許容誤差5%であれば、サンプリングからの推定が母集団の実態と±5%以内の誤差におさまる、という意味です。想定回答比率(P)とは、ある事柄について母集団で想定される回答比率です。今回の場合、Pは50%を想定します。
(図6)許容誤差とサンプルサイズ
- 資料:
- 杉山明子「現代人の統計3 社会調査の基本」(朝倉書店 1984 p.34~36)を元にヤフーが作成
得票率の差10%を統計的にも正しく予測しようとすると、誤差を±5%におさめたいので、その州で少なくとも400サンプルは必要ということになります。得票率の差が4%では誤差は±2%にしたいので2500サンプル、得票率の差が2%の場合は誤差±1%にしたいので10000サンプル以上が必要です。
例えば得票率の差が0.3%の僅差だったニューハンプシャー州の場合、この結果を予測するために必要なサンプルサイズを公式に当てはめて計算すると約45万サンプルとなります。
つまり州内の得票数74万に対して半数以上の事前調査が必要だったという試算です。
これでは全米で何百万サンプル以上の巨大な調査を行わなければならないという見立てになってしまいます。
ただ現実的には、そのような大規模調査は実施困難です。主要メディアであっても、全米で数千サンプル程度の調査がほとんどであり、今回のような接戦を予測するには圧倒的にサンプルサイズが不足していたということになります。
(図7)各社の得票率予測とサンプルサイズ

データは選挙情報サイト「Real Clear Politics」から照合。RV(Registered Voters)は登録済み有権者、LV(Likely Voters)はRVのうち、当日選挙に行きそうな有権者。日付は調査最終日を記載。
- 資料:
- BBCのUS ELECTION 2016(外部サイト)を元にヤフーが作成
このように、僅差の勝敗を統計的に正しく予測するためには、州ごとに巨大なサンプルを必要とするため、今回の米大統領選予測は非常に困難であったと言えるでしょう。それほどきわどい激戦だったアメリカ、そしてトランプ氏の今後の動きからも目が離せませんね。
いかがでしたでしょうか。今後ともYahoo! JAPANビッグデータレポートをよろしくお願いします。