
データは「21世紀の原油」と例えられ、ビジネスの源泉になる可能性を秘めているといわれています。現在、多くの企業がデータ活用を成長戦略の一部として掲げ、各社が取り組みを進めています。
また、データとAIを用いることで、医師以上の精度で腫瘍を検出したり、囲碁でプロ棋士に60連勝したりと、従来のコンピューターでは成し得なかったことも可能になりはじめています。
ヤフーは2017年2月、データやAIを活用することで、より多くの企業や自治体、研究機関の活動をサポートしていきたいという思いから「データフォレスト構想」を立ち上げました。
ここからは、2018年11月開催の「Data Scientist Fes2018」講演から、CDO(Chief Data Officer)の佐々木が語る「データフォレスト構想」およびヤフーならではの強みをご紹介します。
第3次人工知能ブームを支えるもの
現在は「第3次人工知能ブーム=機械学習の時代」だといわれています。これはビッグデータ、インフラ、サイエンスの3つの要素が整ってきたことが背景にあります。
1)ビッグデータ
大量のデータがないと有効に機能しません。データ量は、年率1.4倍で指数関数的に増加しています。
2)インフラ
大量のデータを処理するために、「Hadoop」などの分散処理技術やスパーコンピューターもだいぶ定着してきました。大きなデータを処理する技術も進歩しています。
3)サイエンス
ビッグデータを処理できるインフラがあっても、処理のためのアルゴリズムがなければ有効に活用できません。
「ディープラーニング」を含む機械学習の技術によってデータが意味をなしてきました。

ヤフーのビッグデータ活用
ヤフーでは、ビッグデータを活用したサービス運用を行うため、以下のようなビッグデータ、データ基盤、サイエンス、組織をつくってきました。
1)ビッグデータ
ヤフーの提供サービスは100以上、月間ログインユーザー数は4000万以上と、年々そのデータは増えています。一人あたりから取得できるデータ量は、2013年から2017年までに約20倍になっています。
また、サービスが多岐にわたるため、データの内容が多様性も兼ね備えているところがヤフーの強みで、「マルチビッグデータ」と呼んでいます。

2)データ基盤
ヤフーでは大量のデータを効率的に処理するため、必要なデータ基盤と環境を兼ね備えています。例えばデータ分析を支える基盤として、「Hadoop」(※)を自社で保有、運用するなど、膨大なデータ処理を支えるには十分な規模を持っています。
※Hadoop:
大規模データの蓄積・分析を分散処理技術によって実現するオープンソースのミドルウェア
ヤフーが独自に開発したスーパーコンピューター「kukai」の実用化もはじまりました。kukaiはディープラーニングの処理に特化しており、社内の需要拡大のため、規模を従来の2.5倍にまで拡大しました。
また、大規模なディープラーニングの処理で課題となるのが電気代です。スパコンは電気の消費量が多くなるため、省エネのスパコンをつくりたいと開発。世界的なスパコンの省エネ性能ランキング「GREEN500」で2位となりました(2017年6月発表)。

3)サイエンス
ヤフーの膨大なビッグデータから価値を作り出すためのサイエンスも持っています。
・ディープラーニングを含む機械学習
Yahoo!ニュースやYahoo!ショッピングなどのサービスにもデータが生かされています。
・自然言語処理
Yahoo!ニュースのレコメンドの仕組み、広告の表示などに生かされています。
・情報検索
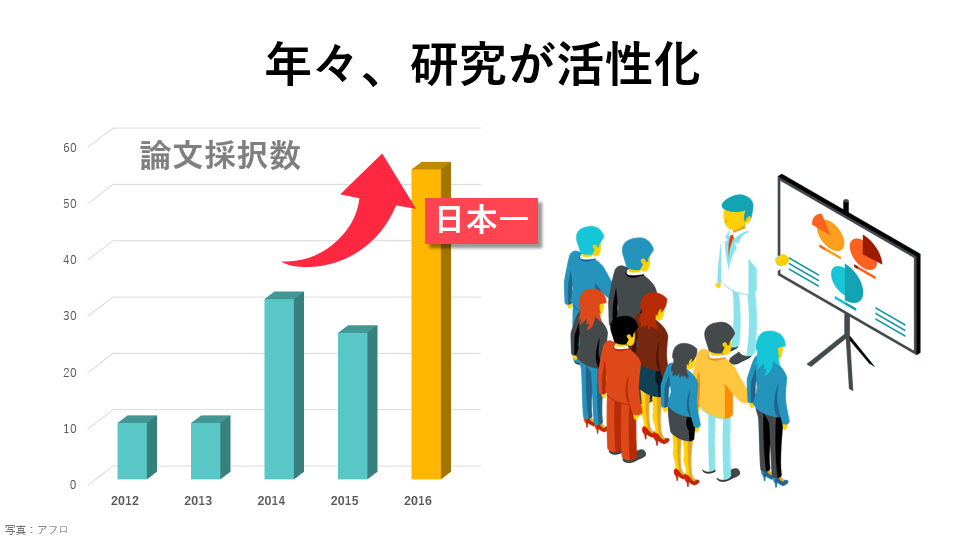
また、ビッグデータ活用について外に発表することも積極的に行っており、世界最先端のデータサイエンス領域のトップクラスの学会では、日本の企業の中で最も多くの論文が採択されています。(2018年2月の調査結果より)
4)組織
ヤフーの多種多様なビッグデータを支えるための組織づくりも進んでいます。ユーザーが何を買ってなにを検索して、何を知ろうとしたかなど、横串でデータを把握する必要があると考え、各サービスに対してデータとサイエンスを活用して横断的に支援する組織が2015年に設立されました。現在は約500人の人材がデータ部門でヤフーのサービスを支えています。
また、2017年に社内全体のデータに関する指揮をとる役CDO(チーフデータオフィサー)を設置。2018年からはグループ会社にもデータ責任者やCDOを配置することで、グループ全体でデータ活用を支える体制づくりを進めています。
ちなみに、ヨーロッパやアメリカの大手企業を中心とした世界の時価総額上位100社の30社近くがCDOを置いています。日本では、CDOがいる企業は、まだヤフーを含む2社のみです。(2018年1月時点:自社調べ)

ヤフーの「データフォレスト構想」とは
一つの企業が持っているデータは限られていますが、たとえば
- ヤフーと企業のデータを組み合わせることで企業の業績が上がる
- ヤフーと自治体のデータを組み合わせることでパブリックサービスの質が上がる
- ヤフーと研究機関のデータを組み合わせることで研究の成果が上がる
など、できることは日本中にまだまだたくさんあると考えています。
データやAIを活用することで、より多くの企業や自治体、研究機関の活動をサポートしていきたいという思いから「データフォレスト構想」を立ち上げました。「データフォレスト」とは、森の実りを動物や植物が分け合って、森が成長していくエコシステム(生態系)になぞらえて名づけました。
将来的には、ヤフーと企業、ヤフーと自治体、ヤフーと研究機関という関係だけではなく、企業間、自治体間、研究機関間でもデータを相互利活用することで、参加する企業や自治体が成長し、さらに多くのデータが集まるシステムを目指していきたいと思っています。
現在、約20社の企業様と、商品開発、需要予測などといったテーマで実証実験を進めています。その一部をご紹介します。
ヤフーの「データフォレスト構想」で進めている実証実験
1)消費者ニーズ
Jリーグさんとの取り組みの中で発見した消費者ニーズの例をご紹介します。コアなJリーグファンを増やすことを目的として、来場施策を検討している中、既存来場者の興味関心を分析したところ、ライト層はヘビー層と比較し、「Jリーグ」「DAZN」といったサッカーに関する言葉より、「キッズ」「ジュニア」「幼稚園」といったようなファミリー層を意識させる言葉の検索が多いことがわかりました。
また、子ども関連のニーズをもう少し深掘りしてみると、子どもと出かける先や「イベント」「自由研究」といった子どもの体験に関して興味関心があることがわかりました。サッカー観戦を子どもと楽しめる企画を、ファンのコア化の施策の1つとして検討していくヒントが得られた例となります。

2)商品開発
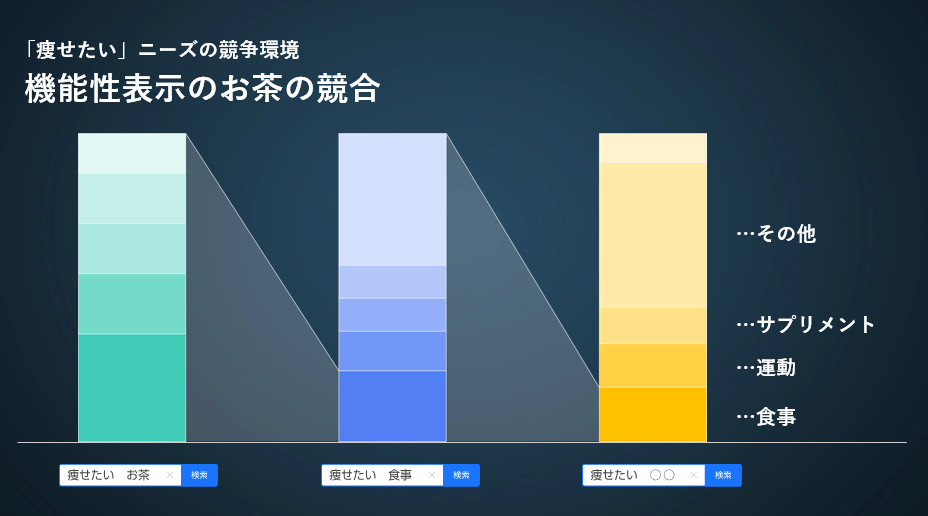
「痩せたい」というニーズをターゲットにした、機能性飲料(お茶)の商品開発のケースをご説明します。
「体脂肪を減らす」「脂肪の吸収を抑える」といったうたい文句のお茶は近年続々と増えていますが、「痩せたい」ニーズを満たすことを考えると、実は他の飲み物や酵素、運動やサプリメントなども競合にあたります。同類の商品だけではなく、別商品、別カテゴリーで、どのような競合が存在するかが検索データの分析からわかりました。
3)自治体との実証実験
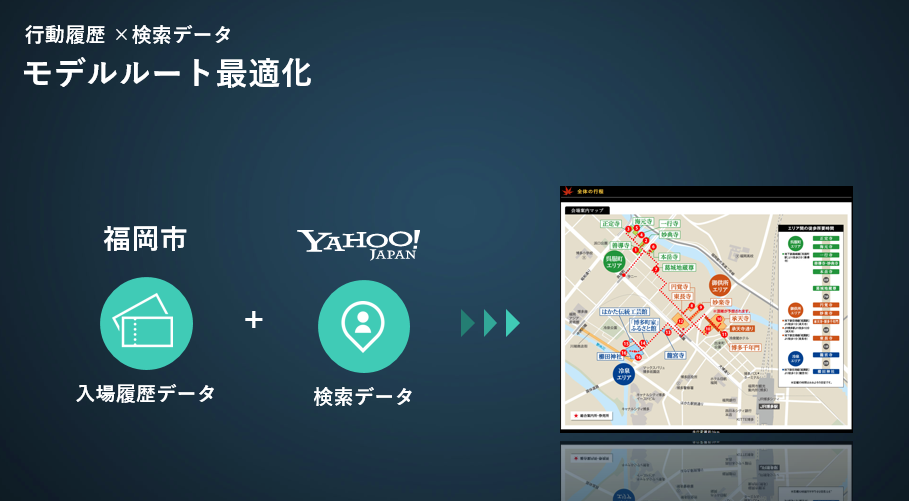
福岡市の伝統的な地域イベント「博多旧市街ライトアップウォーク2018」に関する実証実験をご紹介します。これは、ライトアップされた神社仏閣、各種イベントなどを楽しみながら参加者が博多旧市街をスムーズに巡れるようにするというものです。
昨年度の各会場の入場履歴データにヤフーが保有するデータから読み取れる混雑予測情報を掛け合わせて、最適なモデルルートを作成しました。事前に参加者にこのルートをご案内することで人の流れが分散し、混雑を緩和できました。
まだ実証実験の段階ですが、今後は実証実験、製品・サービス化、事業化という3ステップで進めていく予定です。
2018年度は、現在行っている実証実験を継続して成功事例を増やすとともに、成功事例のパターンを整理し、横断的に展開できるよう製品・サービス化を進めていきます。2019年度には、それをデータソリューションとして事業化していく予定です。また、将来的には大企業や大都市だけではなく商店や全国の自治体、研究機関の皆様とも取り組みをさせていただきたいです。
個々の企業や自治体が単独でデータを使うのではなく、日本全体で日本のデータを利活用できる世界が作れれば、よりよいものづくりや、より便利なまちづくり、研究の発展が可能になると考えています。
